DeepSeek-R1模型1.5b、7b、8b、14b、32b、70b和671b有什么区别?参数量的区别,B代表十亿的意思,1.5b代表15亿参数量的意思。除了尺寸大小方面,性能特点、适应场景有啥区别?运行模型的硬件配置有什么限制要求?服务器百科fwqbk.com整理671B是基础大模型,1.5B、7B、8B、14B、32B、70B是蒸馏后的小模型,它们的区别主要体现在参数规模、模型容量、性能表现、准确性、训练成本、推理成本和不同使用场景:

 DeepSeek-R1模型尺寸版本区别
DeepSeek-R1模型尺寸版本区别
DeepSeek-R1不同尺寸模型版本区别对比
DeepSeek-R1-671b是基础大模型尺寸,其他的蒸馏后的小模型,关于不同尺寸的DeepSeek-R1版本介绍、参数量、特点、使用场景和硬件配置,可以参考下表:
| DeepSeek模型版本 | 参数量 | 特点 | 适用场景 | 硬件配置 |
|---|---|---|---|---|
| DeepSeek-R1-1.5B | 1.5B |
轻量级模型,参数量少,模型规模小
|
适用于轻量级任务,如短文本生成、基础问答等
|
4核处理器、8G内存,无需显卡 |
| DeepSeek-R1-7B | 7B | 平衡型模型,性能较好,硬件需求适中 |
适合中等复杂度任务,如文案撰写、表格处理、统计分析等
|
8核处理器、16G内存,Ryzen7或更高,RTX 3060(12GB)或更高 |
| DeepSeek-R1-8B | 8B | 性能略强于7B模型,适合更高精度需求 | 适合需要更高精度的轻量级任务,比如代码生成、逻辑推理等 | 8核处理器、16G内存,Ryzen7或更高,RTX 3060(12GB)或4060 |
| DeepSeek-R1-14B | 14B | 高性能模型,擅长复杂的任务,如数学推理、代码生成 |
可处理复杂任务,如长文本生成、数据分析等
|
i9-13900K或更高、32G内存,RTX 4090(24GB)或A5000 |
| DeepSeek-R1-32B | 32B | 专业级模型,性能强大,适合高精度任务 | 适合超大规模任务,如语言建模、大规模训练、金融预测等 | Xeon 8核、128GB内存或更高,2-4张A100(80GB)或更高 |
| DeepSeek-R1-70B | 70B | 顶级模型,性能最强,适合大规模计算和高复杂任务 | 适合高精度专业领域任务,比如多模态任务预处理。这些任务对硬件要求非常高,需要高端的 CPU 和显卡,适合预算充足的企业或研究机构使用 | Xeon 8核、128GB内存或更高,8张A100/H100(80GB)或更高 |
| DeepSeek-R1-671B | 671B | 超大规模模型,性能卓越,推理速度快,适合极高精度需求 |
适合国家级 / 超大规模 AI 研究,如气候建模、基因组分析等,以及通用人工智能探索
|
64核、512GB或更高,8张A100/H100 |
如何选择?资源有限选择选1.5B-14B,性价比更高;运行企业复杂任务选择32B-70B平衡性能与成本;尖端科研/高精度需求:优先671B,但需配套基础设施。
不同DeepSeek-R1模型尺寸大小,如下图:
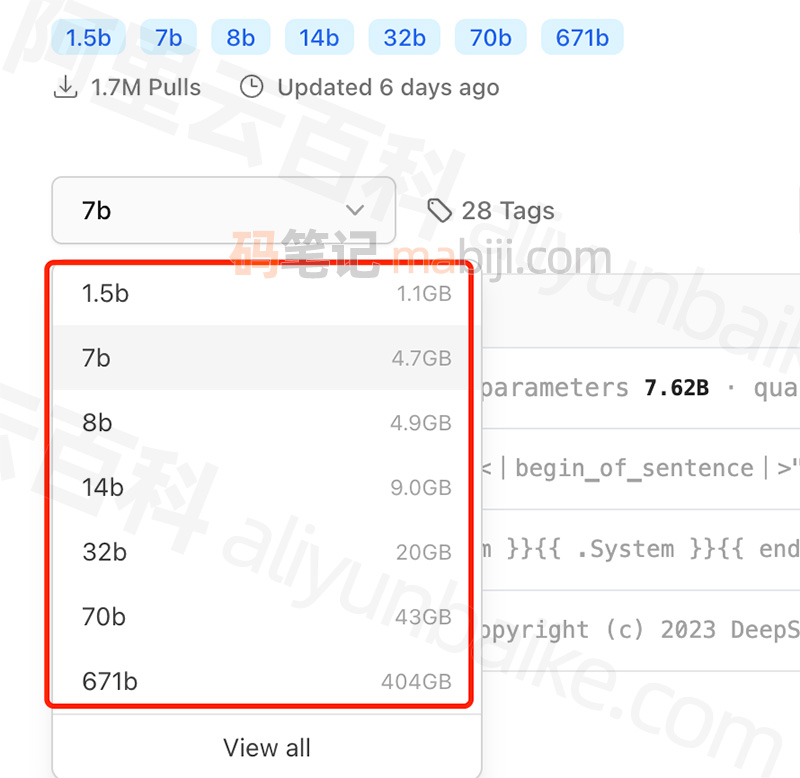 DeepSeek-R1不同模型尺寸大小
DeepSeek-R1不同模型尺寸大小
参数规模
参数规模的区别,模型越大参数数量逐渐增多,参数数量越多,模型能够学习和表示的知识就越丰富,理论上可以处理更复杂的任务,对各种语言现象和语义理解的能力也更强。比如在回答复杂的逻辑推理问题、处理长文本上下文信息时,70B的模型可能会比1.5B的模型表现得更出色。
- 671B:参数数量最多,6710亿参数量,模型容量极大,接近人类专家级推理能力,能够学习和记忆海量的知识与信息,对各种复杂语言模式和语义关系的捕捉能力最强。
- 1.5B-70B:参数数量相对少很多,模型容量依次递增,捕捉语言知识和语义关系的能力也逐渐增强,但整体不如671B模型丰富。
关于DeepSeek部署安装教程,可以部署到本地电脑、阿里云或腾讯云上,小白零基础教程如下:
- 本地部署:一招解决DeepSeek服务器繁忙,拒绝稍后再试!
- 阿里云:小白必看:DeepSeek安装部署——阿里云PAI零代码1分钟成功教程!
- 腾讯云:1分钟:DeepSeek-R1大模型一键部署教程by腾讯云HAI,如此简单!
- 京东云:京东云DeepSeek安装部署教程,言犀AI开发支持DeepSeek-V3和R1大模型
准确性和泛化能力
随着模型规模的增大,在各种基准测试和实际应用中的准确性通常会有所提高。例如在回答事实性问题、进行文本生成等任务时,大规模的模型如 70B、32B 可能更容易给出准确和合理的答案,并且对于未曾见过的数据和任务的泛化能力也更强。小模型如 1.5B、7B 在一些简单任务上可能表现尚可,但遇到复杂或罕见的问题时,准确性可能会降低。
- 671B:在各类任务上的准确性通常更高,如在数学推理、复杂逻辑问题解决、长文本理解与生成等方面,能更准确地给出答案和合理的解释。
- 1.5B-70B:随着参数增加准确性逐步提升,但小参数模型在面对复杂任务或罕见问题时,准确性相对较差,如 1.5B、7B、8B 模型可能在一些简单任务上表现尚可,但遇到复杂问题容易出错。
训练成本
模型参数越多,训练所需的计算资源、时间和数据量就越大。训练70B的模型需要大量的GPU计算资源和更长的训练时间,相比之下,1.5B的模型训练成本要低得多。
- 671B:训练需要大量的计算资源,如众多的高性能 GPU,训练时间极长,并且需要海量的数据来支撑,训练成本极高。
- 1.5B-70B:训练所需的计算资源和时间相对少很多,对数据量的需求也相对较小,训练成本较低。
推理成本
推理成本在实际应用中,推理阶段大模型需要更多的内存和计算时间来生成结果。例如在部署到本地设备或实时交互场景中,1.5B、7B等较小模型可能更容易满足低延迟、低功耗的要求,而 70B、32B等大模型可能需要更高性能的硬件支持,或者在推理时采用量化等技术来降低资源需求。
- 671B:推理时需要更多的内存来加载模型参数,生成结果的计算时间也较长,对硬件性能要求很高。
- 1.5B-70B:在推理时对硬件要求相对较低,加载速度更快,生成结果的时间更短,能更快速地给出响应。
适用场景
轻量级应用,需要快速响应需求可以选择1.5B、7B 这样的小模型可以快速加载和运行,能够在较短时间内给出结果,满足用户的即时需求,小模型适合一些对响应速度要求高、硬件资源有限的场景,如手机端的智能助手、简单的文本生成工具等;在科研、学术研究、专业内容创作等对准确性和深度要求较高的领域,选择70B、32B等大模型更适合。
- 671B:适用于对准确性和性能要求极高、对成本不敏感的场景,如大型科研机构进行前沿科学研究、大型企业进行复杂的商业决策分析等。
- 1.5B-7B:适合对响应速度要求高、硬件资源有限的场景,如移动端的简单智能助手、轻量级的文本生成工具等,可快速加载和运行。
- 8B-14B:可用于一些对模型性能有一定要求,但又没有超高性能硬件支持的场景,如小型企业的日常文本处理、普通的智能客服等。
- 32B-70B:能满足一些对准确性有较高要求,同时硬件条件相对较好的场景,如专业领域的知识问答系统、中等规模的内容创作平台等。
关于DeepSeek大模型费用价格,请参考这篇文章:DeepSeek模型价格:R1+V3最新收费标准,低至0.1元百万tokens
注意:2025云服务器大降价:阿里云99元服务器新老同享,续费也是99元1年;腾讯云服务器秒杀38元1年起;京东云服务器秒杀36元一年;华为云服务器最便宜29元一年起。配置从2核2G3M、2核4G5M、2核8G、4核8G、4核16G、8核16G、8核32G、16核32G、16核64G等CPU内存皮配置可选,详细移步到官方活动页面:
- 阿里云官方活动:https://t.aliyun.com/U/bLynLC
- 腾讯云官方优惠:https://curl.qcloud.com/oRMoSucP
- 京东云服务器:https://jdyfwq.com/
- 华为云服务器:https://hwyfwq.com/
发表评论